


LLM Hallucination and How to Build a Reliable Chatbot
LLM hallucination is a failure where a language model gives you an answer that sounds confident, reads perfectly, and is completely wrong. It is the single biggest reason AI chatbots fail in production. The model is not lying on purpose. It was built to produce text that looks right, not text that is true, and most of the time nobody told it the difference.
This is not a rare edge case. Across a 2026 benchmark of 37 models, hallucination rates ranged from 15% to 52% depending on the model and the task. If you are building a chatbot for a real business, this is the problem that will embarrass you. A support bot that invents a refund policy. A medical assistant that fabricates a drug interaction. A finance tool that quotes a number that never existed. I have spent years shipping AI in healthcare and finance, where a confident wrong answer is not a bug, it is a liability. So let me show you why LLMs hallucinate, where it does the most damage, and the exact architecture I use to build a chatbot that stays grounded.
What is LLM hallucination?
An LLM hallucination is any output that is fluent and plausible but not supported by facts or by your data. The word makes it sound exotic. It is not. It is the normal behavior of the model showing through.
A large language model has one job. Given some text, it predicts the most probable next word, then the next, then the next. It learned those probabilities from a huge amount of text. It did not learn a database of facts you can look up. So when you ask it something, it does not retrieve an answer. It generates one that is statistically likely to follow your question.
Most of the time, the most likely text is also correct, because correct text was common in its training. But when the model has a gap, it does not stop and say “I do not know.” It fills the gap with the most plausible words it can find. That filler is the hallucination. The dangerous part is that it comes out in the same confident tone as a real answer.
Why do LLMs hallucinate?
There is no single cause. In production, hallucination comes from a handful of root reasons, and you fix them in different ways.
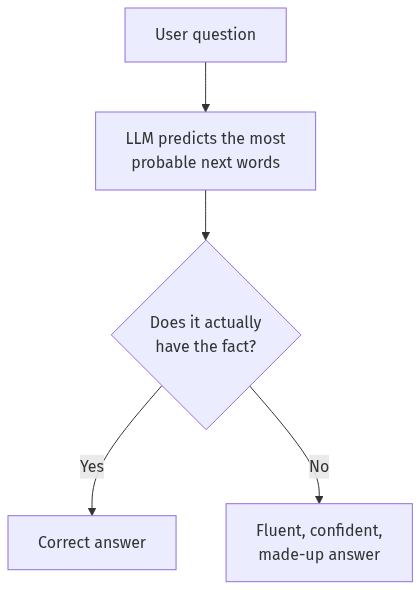
Here are the causes I see most often when I audit a broken bot:
- The model never knew. The fact is about your private data, your prices, your policies, your customer. That was never in its training, so it guesses.
- The model knew, but stale. Training has a cutoff date. Ask about anything newer and it answers from an old world.
- The prompt invited it. Vague or leading questions push the model to produce something rather than admit a gap.
- The context got lost. On long conversations the model runs out of room and silently forgets earlier facts, then fills the hole.
- It was rewarded for confidence. These models were tuned to be helpful and fluent. A hedged “I am not sure” scores worse in training than a smooth answer, so the model learned to sound certain.
Notice what is not on this list: the model being “dumb.” The smartest model on the market still hallucinates, because hallucination is not a knowledge problem. It is a design property. That is why throwing a bigger model at it does not fix it.
Where hallucination does the most damage
In a casual chatbot, a made-up answer is annoying. In a business chatbot, it is a real cost. I have watched the same pattern play out across industries.
In healthcare, I worked on systems where an answer is read by a clinician under time pressure. A fabricated dosage or a made-up contraindication is not a typo, it is a patient-safety event. In finance, a chatbot that invents a fee or misstates a rule creates a compliance problem the moment it hits a customer. Even in plain customer support, a bot that confidently promises a refund that does not exist creates a chargeback, an angry user, and a screenshot on social media.
The numbers back this up. Stanford researchers found hallucination rates of 58% to 88% on legal queries across major models, exactly the kind of high-stakes domain where a confident wrong answer does real damage. The harder and more specialized the question, the more the model reaches for plausible filler.
The common thread is trust. People believe a fluent answer. The more natural the chatbot sounds, the more damage a wrong answer does, because nobody double-checks something that sounds sure of itself. So the goal of good ai chatbot development is not a model that sounds smarter. It is a system that knows the edge of what it knows.
How to build an AI chatbot that does not hallucinate
You cannot delete hallucination from the model. You can build a system around it so the model is never the source of truth in the first place. This is the core shift. Instead of asking the model what it remembers, you hand it the facts and ask it to answer using only those.
That pattern has a name: a RAG system. RAG stands for retrieval augmented generation. The idea is simple. Before the model answers, you retrieve the relevant facts from your own trusted data and put them in front of it.

Walk through what changes. A user asks your support bot about the refund window. An ungrounded bot answers from its training, which knows nothing about your policy, so it invents “30 days” because that is common. A rag chatbot first searches your actual policy documents, finds the paragraph that says “14 days,” puts that text in the prompt, and tells the model to answer from it. Now the answer is 14 days, and you can show the user the exact source.
This is the foundation of every reliable llm app I have shipped. The model still writes the sentence, which is what it is good at. But the facts come from your data, which is what it is bad at remembering. You have split the job along the line where the model is strong and where it is weak.
The grounding stack: how to make it actually reliable
RAG alone is a big improvement, but on its own it is not enough. A retrieval step can pull the wrong document, or the right document with a subtle gap, and the model will still fill that gap. So in production I stack several layers, each one catching what the last one missed.
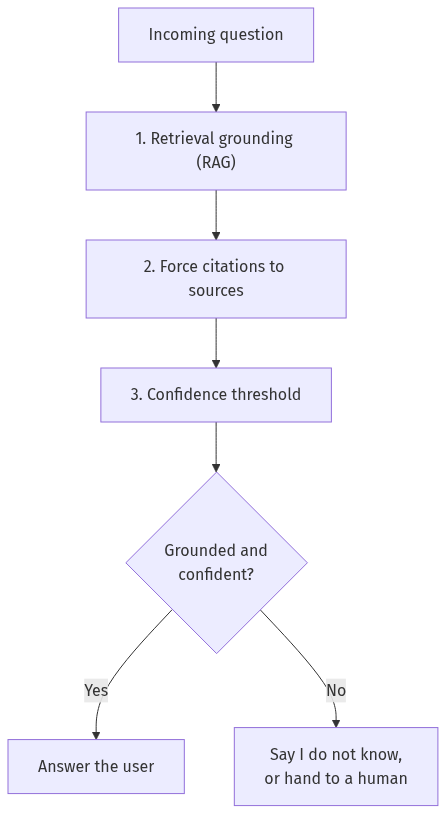
Here is what each layer does and why it earns its place.
Layer 1, retrieval grounding. Pull the relevant facts from your data first. This is the RAG step. It removes the most common cause of hallucination, the model answering from memory it does not have.
Layer 2, forced citations. Require the model to quote or link the source for every claim. This does two things. It gives the user a way to verify, and it makes the model’s own answer easier to check automatically. If a sentence has no source, you flag it.
Layer 3, a confidence threshold. Score how well the retrieved documents actually match the question. If the best match is weak, the honest answer is that you do not have good information, not a guess dressed up as fact.
Layer 4, a graceful fallback. When the system is not confident, it should say so and route the user to a human or a search box. “I do not have that information” is a feature, not a failure. It is the single most underused sentence in ai chatbot development.
The payoff here is measurable, not just theory. On grounded summarization tasks, the best 2025 systems brought hallucination down to roughly 0.7% to 1.5%, compared to the double-digit rates the same class of models produce when answering from memory alone. Grounding is the lever that moves the number.
The difference between an ungrounded bot and this stack is night and day. Here is the comparison I draw for clients:
| Dimension | Ungrounded LLM chatbot | Grounded RAG chatbot |
|---|---|---|
| Source of answer | The model’s memory | Your trusted documents |
| Hallucination risk | High and invisible | Low and traceable |
| Can you verify it? | No, there is no source | Yes, every claim cites a source |
| Handles “I do not know” | Rarely, it guesses | Yes, by design |
| Stays current | Frozen at training cutoff | As fresh as your data |
| Safe for healthcare or finance | No | With the full stack, yes |
What still breaks, even with a good stack
I would be lying if I told you this makes hallucination disappear. It does not. It makes it rare, visible, and recoverable, which is the realistic goal. Here is what still goes wrong in production and what I watch for.
Retrieval misses. If your search pulls the wrong paragraph, the model grounds confidently on the wrong fact. Good retrieval is its own engineering problem (this is exactly where knowledge graphs and GraphRAG help), and most “RAG is not working” complaints I get are actually retrieval problems, not model problems. A real example: a support bot once answered questions about the wrong product tier because the retrieval step matched on the product name and ignored the tier, so it confidently quoted enterprise pricing to a free user. The model did nothing wrong. The retrieval handed it the wrong document, and a wrong source produces a wrong answer every time, no matter how good the model is.
Conflicting sources. When two documents disagree, the model picks one, often silently. You have to detect the conflict and surface it rather than hide it.
The confident tone. Even a grounded answer is delivered with the same smoothness as a wrong one. Users still need the citations to tell the difference, which is why layer 2 is not optional.
This is the part most tutorials skip, and it is exactly the part that decides whether your chatbot survives contact with real users. A demo that works in a five-minute video and a system that holds up at 2am under real questions are two very different things.
How do you test a chatbot for hallucination?
You cannot fix what you do not measure, and this is where most teams stop too early. A bot that looked fine in a demo will still drift once real users ask real questions, so testing has to be continuous, not a one-time check before launch.
Here is the testing approach I set up for every production chatbot.
Build an evaluation set. Collect 100 to 200 real questions your users actually ask, each paired with the correct answer and the source it should come from. This is your ground truth. Without it, you are guessing whether the bot is improving or getting worse.
Measure groundedness, not just correctness. For every answer, check whether each claim traces back to a retrieved source. An answer can be correct by luck and still ungrounded, which means it will fail on the next question. Groundedness is the metric that predicts future behavior.
Use a model to grade the model. Run a second LLM as a judge that reads each answer and its sources and flags any sentence not supported by the retrieved text. This is not perfect, but it scales to thousands of answers in a way human review cannot, and it catches the obvious failures fast.
Track the “I do not know” rate. A healthy chatbot refuses to answer some questions. If that rate is zero, your bot is guessing on everything. If it is too high, your retrieval is weak. Watching this number tells you which layer to fix.
Re-run it on every change. New model version, new prompt, new data: run the full evaluation set again before it ships. Hallucination regressions are silent, and the only way to catch them is to test the same questions every time. This is the part of ai chatbot development that separates a system you can trust from one you are hoping holds together.
Frequently asked questions
Why do LLMs hallucinate?
Because a language model predicts the most probable next words, not verified facts. When it lacks the real information, it fills the gap with plausible-sounding text instead of admitting the gap. The output looks identical to a correct answer, which is what makes it dangerous.
Can you fully stop LLM hallucination?
No, you cannot remove it from the model itself, because it is a property of how the model works. You can build a system around the model, using retrieval grounding, forced citations, confidence thresholds, and a fallback, that makes hallucination rare, visible, and recoverable. That is the realistic and achievable goal.
Does RAG eliminate hallucination?
RAG dramatically reduces it by feeding the model your real data instead of relying on its memory. But RAG can still fail if retrieval pulls the wrong document, so it works best as one layer in a larger grounding stack rather than a complete fix on its own.
How do you build an AI chatbot for a business that cannot afford wrong answers?
Start from the assumption that the model will sometimes be wrong, and design so that being wrong is caught. Ground every answer in your own data, require citations, measure retrieval confidence, and let the bot say it does not know. In regulated fields like healthcare and finance, that last step is what makes the system safe to ship.
The takeaway
Hallucination is not a sign your model is bad. It is the model doing exactly what it was built to do, predict fluent text, in a situation where you needed truth. The fix is not a smarter model. It is a system that treats the model as a writer, not a source, and grounds every answer in data you trust.
That shift, from “ask the model what it knows” to “give the model the facts and make it cite them,” is the difference between a chatbot that demos well and one that you can put in front of customers in a field where wrong answers cost money. If you are building one and the stakes are real, that is the architecture I would start from. If you want to talk through your specific case, reach me on LinkedIn or through the contact page.
About the author
Ayaz Qaiser is a senior AI engineer with eight years of experience building machine learning and LLM systems in healthcare and finance, where a confident wrong answer is a real liability. He has shipped a patient diagnostic platform, an AI financial analyst, and production chatbots, and writes about how AI actually behaves once it leaves the demo and meets real users.