


Vibe Checks Aren’t Enough: How to Actually “Unit Test” Your AI Agents
Let’s be real for a second. The barrier to entry for building AI agents has completely collapsed. Between local LLMs running on your MacBook via Ollama and low-code orchestration tools like n8n or Flowise, you can prototype a multi-step RAG agent before lunch.
I’ve written extensively here about building those workflows, leveraging local compute, and engineering context. It’s exciting stuff.
But there is a massive, terrifying gap between a cool weekend prototype and something you can actually deploy into a production environment without breaking out in a cold sweat.
Right now, most developers are stuck in the “vibe check” phase of AI development. You build the agent, you throw five or six different prompts at it, you eyeball the results, and if it doesn’t completely hallucinate or insult you, you ship it.
That is the 2025 equivalent of “it works on my machine.”
If we want to call ourselves engineers in this new paradigm, we have to stop treating LLMs like magic boxes and start treating them like software components. And software components need testing.
But here’s the catch: you can’t unit test an LLM the same way you unit test a React component or a Python function. The game has changed, and if you’re still relying on assert result == expected_string, your testing strategy is already cooked.
It’s time to graduate from prompt engineering to Evaluation Engineering.
The Chaos of Non-Determinism
Why do traditional unit tests fail so spectacularly with generative AI?
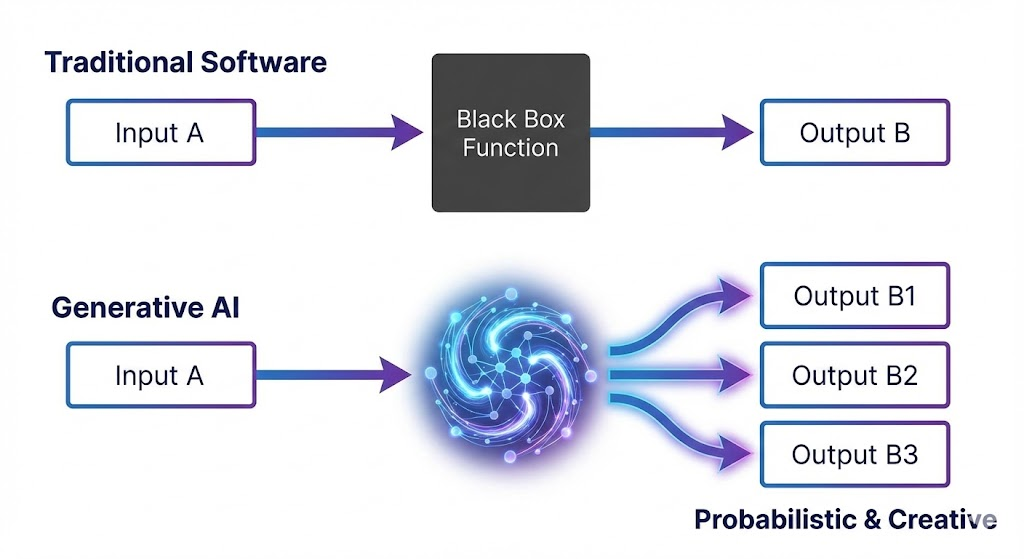
In traditional software development, we rely on determinism. A function that calculates tax, given the same input parameters, should return the exact same floating-point number every single time, down to the last decimal. If it doesn’t, something is fundamentally broken. Our entire CI/CD infrastructure is built on this binary pass/fail reality.
Generative AI is fundamentally inherently stochastic. LLMs are probabilistic engines, predicting the next likely token based on a vast, weighted mathematical landscape. Even with the “temperature” setting turned down to zero, subtle variations in underlying floating-point arithmetic across different GPUs can lead to different outputs.
If you write a traditional unit test expecting your RAG agent to reply with: “The Q3 earnings were $1.2M, up 5% YoY,” but the model decides to output: “Q3 saw earnings of $1.2 million, showing a year-over-year increase of 5%,” your test fails.
Both answers are factually correct. Both are useful to the user. But a rigid string comparison sees them as different as night and day.
Also Read:Stop Trusting Vector DBs Blindly
If we try to force deterministic testing onto non-deterministic systems, we end up with brittle tests that fail constantly, eventually leading teams to just disable the test suite entirely. We need a new framework that embraces the variability of AI while still holding it accountable for quality.
Shifting Mindsets: From “Passing” to “Grading”
If we can’t test for exact string matches, what are we testing for?
We need to shift our mindset from binary passing to qualitative grading. We are no longer checking if the answer is exactly this; we are evaluating if the answer is good enough based on specific criteria.
This is where “Evals” (Evaluations) come in. Evals are the unit tests of the LLM world.
When we build agents, particularly RAG (Retrieval-Augmented Generation) systems or workflow agents, we care about specific quality metrics. We aren’t just “vibe checking”; we are measuring against dimensions like:
- Faithfulness (Groundedness): Did the agent make stuff up, or is its answer derived only from the context retrieved from your vector database? This is the anti-hallucination metric.
- Answer Relevance: Did the agent actually answer the user’s question, or did it ramble on about tangentially related topics?
- Context Relevance: Did the retrieval step actually pull in useful documents, or did it fetch garbage data that confused the LLM?
- Tone and Safety: Is the agent maintaining the professional persona you designed, and is it refusing to generate toxic or harmful content?
You can’t measure “faithfulness” with a regex. You need something intelligent enough to understand the relationship between the provided context and the generated answer.
Also Read:How AI Agents Turn Prompts into Full Workflows
The Secret Sauce: LLM-as-a-Judge
So, how do we automate the grading of these complex, nuanced metrics without having a human review every single output?
Welcome to the concept of LLM-as-a-Judge.
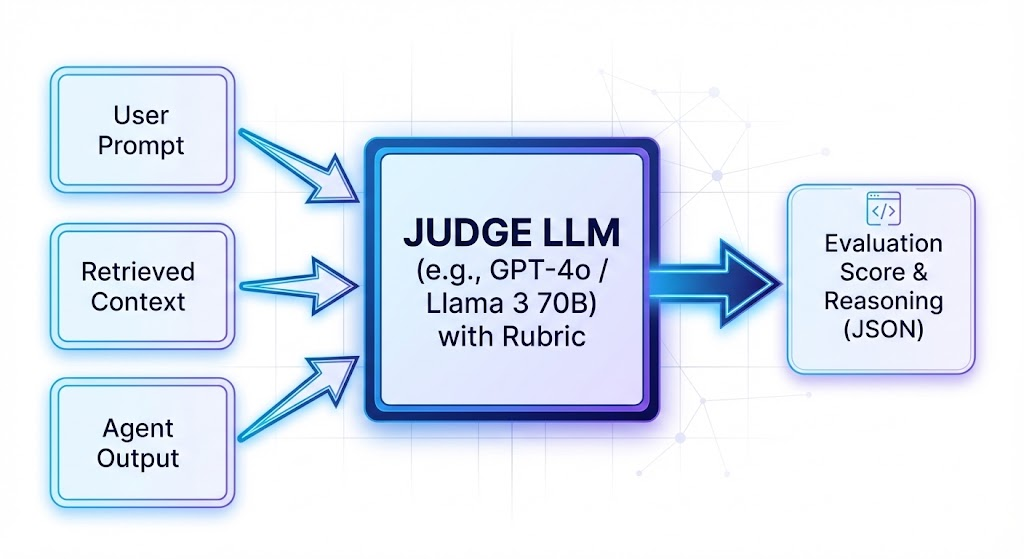
This is currently the most robust pattern for scalable AI testing. The premise is simple, if slightly meta: You use a highly capable “teacher” model to evaluate the outputs of your “student” application model.
Let’s say you are building a customer service agent using a reasonably fast, moderately sized local model like Llama 3 8B. It needs to be quick.
For your evaluations, however, speed isn’t the primary concern—accuracy is. So, in your testing pipeline, you take the input, the retrieved context, and your agent’s generated output, and you feed all three to a larger, more powerful model (perhaps GPT-4o, Claude 3.5 Sonnet, or a massive local model like Llama 3 70B).
You give the “Judge” model a specific rubric prompt. It looks something like this:
You are an expert evaluator for a RAG system. Your task is to assess the ‘Faithfulness’ of the generated answer based ONLY on the provided context.
- Context: [Insert retrieved documents here]
- Generated Answer: [Insert agent output here]
Consider the following criteria: Does the generated answer contain any information that is not present in the context? If yes, the score should be low.
Provide a score from 1 to 5 and a brief reasoning for your score.
The Judge model will analyze the data and return a structured output, perhaps a JSON object containing a score of 4/5 and a reason like: “The answer is largely grounded in the context, but it inferred a date that was not explicitly stated in the source documents.”
Now you have a quantifiable metric. You can set thresholds in your CI/CD pipeline. If the average “Faithfulness” score drops below 4.2 on your test dataset, the build fails. No more vibes—just data.
The Practical Toolkit (Keeping it Local)
You don’t need to build this infrastructure from scratch. The ecosystem around AI engineering is maturing rapidly, and there are incredible open-source tools designed exactly for this.
If you are following my previous posts on keeping your AI stack local and sovereign, you’ll love these.
1. Ragas (Retrieval Augmented Generation Assessment)
Ragas is fantastic because it is specifically meant for evaluating RAG pipelines. It comes with pre-built metrics for the “RAG Triad” Faithfulness, Answer Relevance, and Context Relevance. It’s designed to hook into your existing LangChain or LlamaIndex workflows. You can point Ragas at a local Ollama endpoint to act as the judge, keeping your entire evaluation loop offline.
2. DeepEval (by confident-ai)
DeepEval provides a developer experience that feels very similar to Pytest. You write tests in Python, define your metrics, and assert that your agent’s outputs meet certain criteria.
Python
# A pseudo-code example of what a DeepEval test looks like
from deepeval import assert_test
from deepeval.metrics import FaithfulnessMetric
from deepeval.test_case import LLMTestCase
def test_rag_faithfulness():
# Your agent runs here
actual_output = my_agent.run("What is our return policy?")
retrieved_context = my_agent.get_last_retrieved_docs()
test_case = LLMTestCase(
input="What is our return policy?",
actual_output=actual_output,
retrieval_context=retrieved_context
)
# The Judge LLM evaluates this metric
metric = FaithfulnessMetric(threshold=0.7)
assert_test(test_case, [metric])This looks and feels like actual software engineering. You can run this locally before you push a commit.
Also Read:The Junior Developer Crisis is Real
Integrating Evals into Agentic Workflows
In my last post, we discussed building autonomous agents using tools like n8n and LangGraph. How do evals fit into that visual paradigm?
You cannot have an autonomous agent that doesn’t know when it’s wrong.
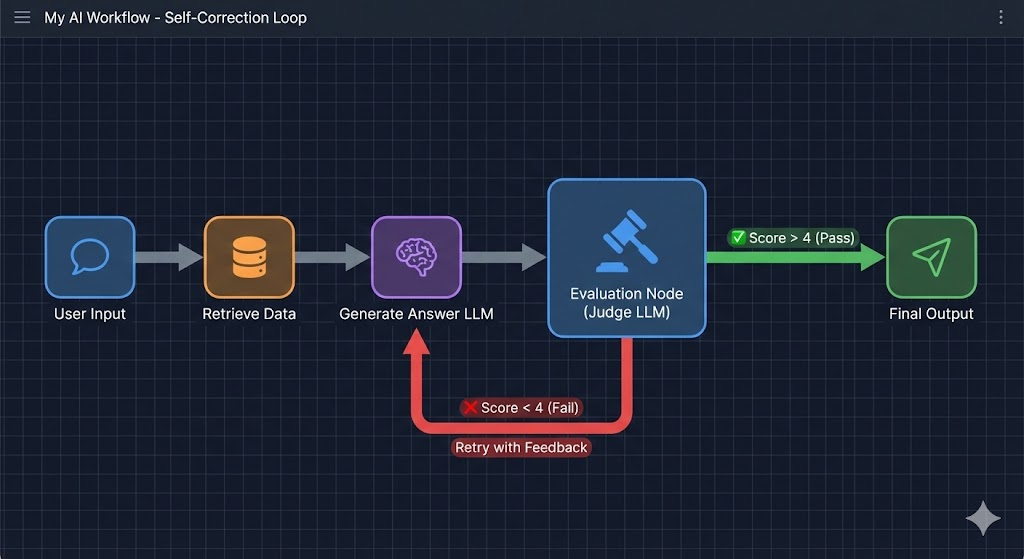
If you are building a complex LangGraph workflow where an agent plans, executes, and reflects, “evaluation” shouldn’t just be an external test script—it should be a node in the graph itself.
Imagine a workflow where an agent generates a draft response to a complex user query. Before showing that to the user, the workflow should pass that draft to a “Critique Node” (an LLM-as-a-Judge).
If the critique node scores the draft low on relevance or accuracy, the workflow loops back to the generation node with feedback, forcing the agent to try again.
This is called “Self-Correction” or “Reflexion,” and it is the hallmark of a truly sophisticated AI system. You are essentially embedding unit tests inside the runtime logic of your application.
Also Read: How AI Browsers Are Becoming Development Tools
The Takeaway
The transition from tinkering with AI to engineering with AI happens when you stop trusting the model blindly and start measuring its performance rigorously.
Vibe checks are fine for hacking on a Saturday night. But if you are building solutions that businesses rely on, you owe it to your users to implement robust Evaluation Engineering.
Start small. Pick one metric like Faithfulness and implement a simple LLM-as-a-Judge test for your primary use case. The first time your automated test catches a hallucination before you ship it, you’ll wonder how you ever lived without it.
Stop guessing. Start measuring. Ship with confidence.