


The Latency War: Why Edge Functions Are Quietly Becoming Mandatory for Real-Time AI Apps
Let’s be real for a second. The current wave of generative AI is incredible, but it has a dirty little secret: it’s often too slow.
We’ve spent the last decade teaching users that “instant” means under 100 milliseconds. Then ChatGPT arrived, and suddenly everyone got comfortable staring at a blinking cursor for three seconds while a model somewhere in an Ohio data center “thought” about the answer.
That delay is acceptable for a chatbot interface where you’re actively waiting for a complex generation. But as we integrate AI into operational workflows real-time voice translation, dynamic e-commerce personalization, autonomous agents, and interactive gaming that latency becomes a UX killer.
If your AI-powered feature lags, users won’t think the AI is complex; they’ll just think your app is broken.
The bottleneck is no longer just model inference time (though that’s still a factor). The new bottleneck is the speed of light and network topology.
This is where Edge Functions stop being a “nice-to-have” optimization and become an architectural necessity for the next generation of AI applications.
Here is why the centralized cloud is failing real-time AI, and why the future of inference is distributed.
The Physics of Centralized AI vs. User Expectations
To understand why the edge is mandatory, we have to look at the current standard architecture.
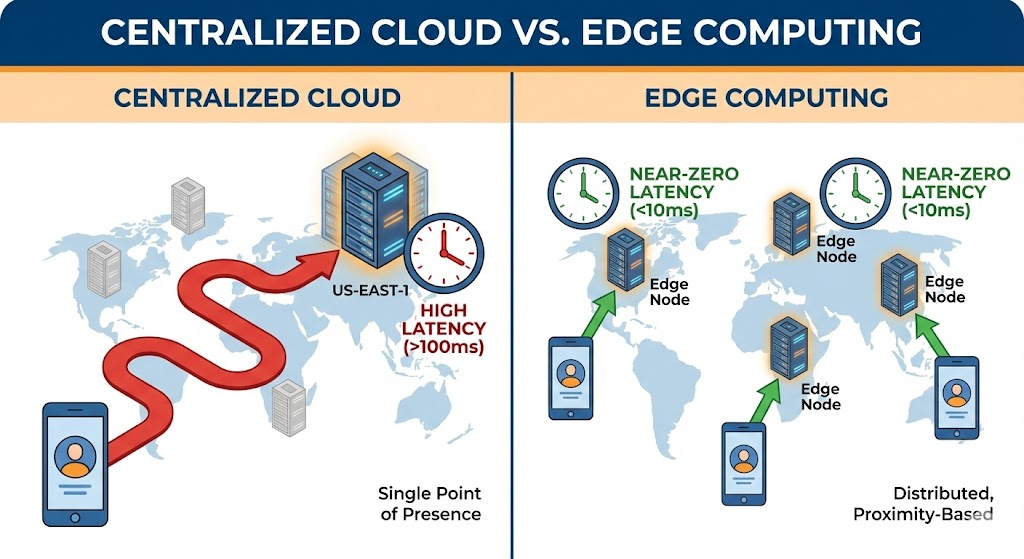
Traditionally, when you build an app, you deploy your backend to a specific region—say, AWS us-east-1 (N. Virginia) or Google Cloud’s europe-west1 (Belgium). If a user in Singapore wants to use your AI feature, their request has to travel via fiber optic cables all the way to Virginia, get processed, and travel all the way back.
Even in ideal network conditions, light in fiber takes time to travel. That round-trip time (RTT) is the baseline latency floor you cannot go below.
Add in network congestion, DNS resolution, TLS handshakes, and the actual GPU inference time for the AI model, and you easily end up with multi-second delays for international users.
The “Real-Time” Definition Shift
In the standard web world, “real-time” usually meant sub-second database updates via WebSockets. In the AI world, the bar is higher.
“Real-time AI” means the model’s output feels synchronous with the user’s input.
- Voice Agents: If there is a 500ms delay between you speaking and the agent processing it, the conversation feels stilted and unnatural.
- Personalization: If an e-commerce site uses AI to re-rank products based on your last click, that re-ranking needs to happen before the next page loads.
Centralized architectures simply cannot guarantee this globally. They discriminate against users based on their geographical distance from the data center.
Enter Edge Functions: Compute Without Geography
Edge computing changes the topology. Instead of deploying your code to one central server, you deploy it to a network of hundreds of servers located in cities around the world at the “edge” of the network, closer to the end-user.
When we talk about “Edge Functions” (think Vercel Edge Middleware, Cloudflare Workers, or Netlify Edge Functions), we are talking about lightweight, JavaScript/Wasm runtimes that spin up instantly in the data center geographically closest to the user issuing the request.
Also Read:5 AI Developer Trends Shaping 2026
How It Differs from Standard Serverless (e.g., Lambda)
A standard AWS Lambda function might still suffer from cold starts and is usually pinned to a specific region. An Edge Function is designed to be:
- Region-agnostic: The platform routes the request to the nearest node automatically.
- Instant-on: They have virtually zero cold starts because they use lightweight isolates (like V8) rather than spinning up entire containers or VMs.
- Latency-obsessed: They are optimized to execute quickly and terminate quickly.
By moving compute to the edge, we are effectively slashing the network RTT component of total latency. The request hits a server in 20ms instead of 200ms.
The Synergy: Why AI Inference Belongs at the Edge
So, why is this specifically vital for AI right now? It comes down to decoupling training from inference.
You aren’t going to train GPT-5 on Cloudflare Workers. Training requires massive, centralized clusters of H100 GPUs running for months. That will always remain a centralized cloud task.
But inference—the act of asking the finished model a question and getting an answer—is highly distributable.
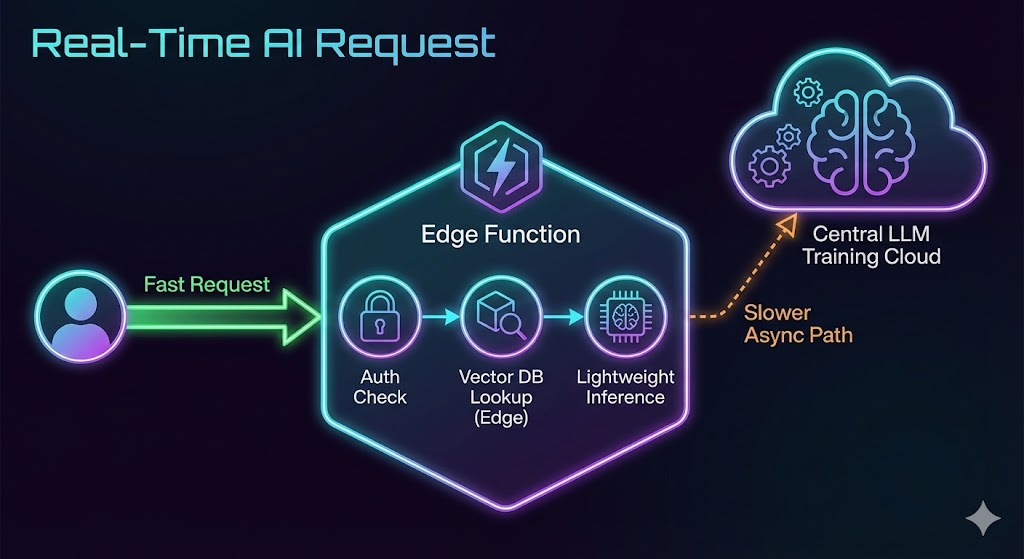
Here is how Edge Functions are powering the real-time AI stack:
A. The AI Gateway and Request Routing
Before a request even hits an expensive LLM API (like OpenAI or Anthropic), you need to do housekeeping. You need to authenticate the user, rate-limit them to prevent abuse, and validate their input.
Doing this in us-east-1 when the user is in Tokyo is wasteful. Edge functions can handle authentication, validation, and sane-checking inputs in single-digit milliseconds right next to the user, rejecting bad requests before they ever incur costs or latency at the central origin.
B. Edge-Based RAG (Retrieval-Augmented Generation)
This is the biggest growth area. RAG involves looking up relevant context from a database before sending a prompt to an LLM.
If your vector database (like Pinecone, Weaviate, or Neon) is centralized, you have to travel to the center to get the context, then travel back to the edge, then maybe to the LLM provider.
The new paradigm is Edge-compatible databases. By replicating read-heavy data (like product catalogs or documentation embeddings) to edge storage, an Edge Function can perform the vector search locally. It gathers the context in milliseconds and then fires off the fully formed prompt to the LLM.
Also Read:PydanticAI: The Modern Way to Write Agents
C. Small Models Running Locally (The Holy Grail)
We are rapidly seeing the rise of smaller, highly capable open-source models (like Llama 3 8B or Mistral) that can be quantized and run on CPU-only or lightweight GPU setups.
While running a full 70B parameter model on a standard Edge Function isn’t quite there yet due to compute limits, it’s coming fast. We already use edge functions to run smaller specialized models for tasks like:
- Sentiment analysis on text input.
- Fast image resizing and basic classification.
- Audio pre-processing before sending to a larger transcription model.
As WebAssembly (Wasm) support for AI runtimes improves, we will see more actual inference happening directly on the edge node, cutting out the central API entirely for simpler tasks.
The Geo-Friendly and Compliance Angle
Speed isn’t the only reason the edge is becoming mandatory. In an increasingly regulated global digital economy, where code runs matters almost as much as how fast it runs.
Data sovereignty laws (like GDPR in Europe or various regulations in India and Brazil) are putting pressure on companies to keep user data within specific geographical borders.
A centralized US-based architecture makes compliance a nightmare. You are constantly shipping German user data to Virginia to process it.
Edge Functions offer a native solution to geo-compliance. Modern edge platforms allow developers to define routing rules based on geography. You can write logic that says: “If the request originates from the EU, only process this data on edge nodes located within the EU borders and access the EU-resident database replica.”
This allows you to build a globally fast application that behaves locally regarding compliance, without managing infrastructure in 20 different regions yourself.
Also Read:Unit Tests vs Vibe Checks for AI Agents
The Pragmatic “Hybrid” AI Stack
If you are a CTO or Lead Architect looking at this, don’t worry—you don’t have to tear down your entire backend tomorrow. The shift to the edge is usually iterative.
We are seeing a “Hub and Spoke” model emerge for modern AI apps:
- The Hub (Central Cloud): This is where your heavy lifting happens. Model training, fine-tuning jobs, massive data warehousing, and your primary write-heavy relational databases live here (e.g., AWS RDS, Snowflake, Databricks).
- The Spokes (The Edge): This is your presentation and inference layer. Your Next.js or Remix frontend runs here. Your API routes that call AI models run here. Read-replicas of your databases live here.
The Workflow Example:
- A user in London asks your AI e-commerce assistant for “sneakers that look like vintage Jordans.”
- A Vercel Edge Function in London intercepts the request.
- It quickly checks a read-replica of your product vector database (hosted on something like Neon or Upstash, also near London) for semantic matches.
- It retrieves top 5 context results in <30ms.
- The Edge Function then constructs a prompt with that context and fires it off to the OpenAI API (which might still be in the US, but the heavy lifting of context gathering is already done).
- The response streams back to the user.
By moving just the context gathering and request orchestration to the edge, you’ve shaved hundreds of milliseconds off the total transaction.
Also Read:How RAG 2.0 Improves AI Accuracy
Conclusion: The Zero-Tolerance Future
The window of tolerance for latency in AI applications is closing rapidly. What was acceptable for a beta research preview in 2023 will not be acceptable for a production consumer application in 2025.
Users expect tech to just work, instantly, regardless of where they are standing on the planet.
Edge functions are no longer just about serving static assets faster. They are the compute layer for the AI era. They are the necessary glue that connects distributed users to centralized intelligence without sacrificing the user experience. If you’re building real-time AI, it’s time to move your logic closer to your users.
Frequently Asked Questions (FAQs)
Are Edge Functions faster than standard Serverless functions like AWS Lambda?
Generally, yes, for two reasons. First, they run geographically closer to the user, reducing network travel time. Second, most modern Edge runtimes (like Cloudflare Workers) use V8 isolates, which have significantly faster “cold start” times than the container-based architecture of traditional Lambda.
Can I run large LLMs like GPT-4 directly on Edge Functions?
Not currently. Edge functions typically have strict limits on execution time, memory, and CPU package size. They aren’t designed for heavy GPU crunching. The current pattern is to use the Edge Function to orchestrate the call to the heavy model, handle context, and stream the response, rather than running the model itself.
Is Edge Computing more expensive than centralized cloud?
It depends on your usage pattern. Edge functions often charge by request or CPU time. For high-traffic applications with lightweight logic, they can be cheaper because you aren’t paying for idle servers. However, if your functions are doing heavy, long-running computations on every request, the costs can creep up. The primary value proposition is performance, not necessarily raw cost reduction.
How do Edge Functions help with SEO for AI apps?
Speed is a major ranking factor for Google (Core Web Vitals). By significantly reducing the Time To First Byte (TTFB) and speeding up dynamic content rendering, Edge Functions directly improve the metrics that search engines prioritize, leading to better SEO outcomes.
Do I need to manage servers in different countries to use Edge Functions?
No. That’s the beauty of platforms like Vercel, Netlify, or Cloudflare. They abstract away the global infrastructure. You write the code once, deploy it, and their platform handles distributing it and routing requests to the nearest node automatically.