

Stop Trusting Vector DBs Blindly: Why Knowledge Graphs (GraphRAG) Are the Missing Piece for Smart AI Agents
We need to have an honest conversation about the state of RAG (Retrieval-Augmented Generation) right now.
If you’ve been following the blog, we’ve covered a lot of ground recently from running local models like Llama 3.1 via Ollama to engineering context and building agentic workflows with tools like n8n. We are all builders here, and we’ve all felt that initial rush of dopamine when we first hooked up a PDF to a Vector Database (like Pinecone or Weaviate) and watched an LLM answer a question based on that data.
It feels like magic. You feel like a genius. You ship it to production.
And then, the inevitable happens. Users start asking real questions. Not just “What is the refund policy on page 3?” but complex, multi-hop questions that require synthesizing information across different documents and domains.
And your beautiful RAG bot completely chokes.
It either says, “I don’t have that information,” even though you know it’s in there, or worse, it confidently hallucinates an answer that stitches together unrelated facts because they happened to use similar keywords.
If this sounds familiar, it’s because you’ve hit the ceiling of what I call “Flat RAG.” You are relying 100% on mathematical similarity in a vector space, and frankly, vectors are great at finding things, but they are terrible at understanding how those things connect.
If we want to move from building impressive demos to building resilient, reasoning AI agents, we need to upgrade our architecture. It’s time to stop looking at our data as a flat list and start treating it like a network.
It’s time to talk about GraphRAG.
The Comfort Zone: The Limit of Vector Embeddings
Before we tear it down, let’s acknowledge why Vector RAG became the standard stack so quickly. It’s elegant and relatively easy to set up.
The workflow is practically muscle memory for AI engineers by now:
- Take your unstructured data (PDFs, Notion docs, Slack history).
- Chunk it into smaller pieces.
- Pass those chunks through an embedding model (like OpenAI’s text-embedding-3-small or a local BERT model) to turn text into a dense vector (a long list of numbers).
- Store those vectors in a Vector DB.
- When a user asks a question, embed the question and perform a Cosine Similarity search to find the “nearest neighbor” chunks.
This works amazingly well for explicit retrieval. If the answer exists in a single, self-contained paragraph, vector search will find it.
Also Read:RAG 2.0 Explained: The Retrieval Shift That Makes AI Finally Accurate
The Fatal Flaw: Similarity ≠ Relationship
The problem is that “semantic similarity” (mathematical closeness in vector space) is not the same as “real-world relationship.”
Vector databases view your knowledge base as a collection of isolated islands. They have no concept of structure, hierarchy, or causality.
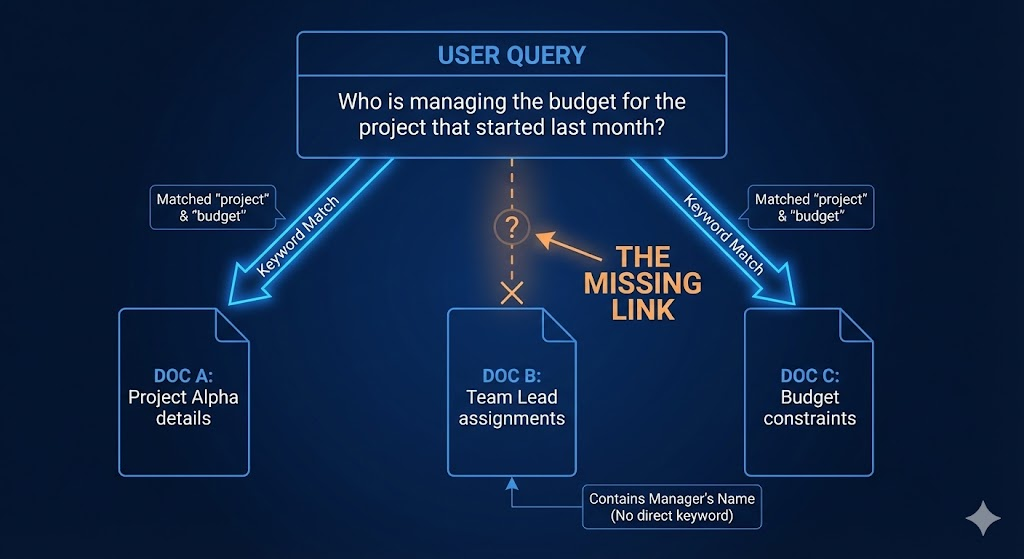
Let’s look at a concrete example. Imagine an internal enterprise RAG system with these three separate documents:
- Document A (HR Policy): “Sarah Chen was promoted to Head of Engineering in Q3.”
- Document B (Project Manifest): “Project ‘Hydra’ is our critical infrastructure overhaul for Q4.”
- Document C (Slack Export): “The Head of Engineering needs to sign off on the Hydra budget by Friday.”
Now, a user asks: “Who is responsible for approving the Hydra budget?”
A standard Vector RAG system is likely to fail here.
- It searches for “Hydra budget.” It might retrieve Document B and Document C.
- The LLM reads those and sees that the “Head of Engineering” needs to sign off.
- But the vector search probably didn’t retrieve Document A, because Document A has zero semantic overlap with “Hydra” or “budget.”
- The bot answers: “The Head of Engineering is responsible, but I don’t know who that is.”
The information is there. The connections exist. But because the data is stored flat, the AI cannot “hop” from Hydra -> Head of Engineering -> Sarah Chen.
This is why your complex RAG agents feel stupid. They lack the connective tissue of knowledge.
Also Read:From Prompting to Context Engineering: How AI Workflows Are Evolving
Enter GraphRAG: Giving AI a “Mental Map”
GraphRAG (Graph-based Retrieval-Augmented Generation) isn’t just a new tool; it’s a fundamental shift in how we structure data for AI consumption. Instead of a flat list of vectors, we model our knowledge as a Graph.
If you’ve ever used GraphQL or looked at a social network analysis, you know what a graph is. It’s composed of two things:
- Nodes (Entities): The “nouns” in your data. People, projects, organizations, concepts, locations. (e.g., Sarah Chen, Project Hydra, Q3).
- Edges (Relationships): The “verbs” that connect the nouns. (e.g., MANAGES, STARTED_IN, REQUIRES_APPROVAL_FROM).
In a Knowledge Graph, our previous example looks like this:
- (Sarah Chen) -[IS_HEAD_OF]-> (Engineering Department)
- (Project Hydra) -[MANAGED_BY]-> (Engineering Department)
- (Project Hydra) -[REQUIRES_SIGNOFF]-> (Budget)
When the AI queries this graph, it doesn’t just perform a blind similarity search. It performs a traversal. It finds the node for “Project Hydra,” looks at its neighbors, sees the requirement for signoff from Engineering, looks at who leads Engineering, and arrives at “Sarah Chen.”
It reasoned its way to the answer through explicit relationships defined in the data structure itself.
Also Read:AI Automation and DevOps: How n8n, Flowise, and LangGraph Are Redefining Workflow
The Microsoft Research Validation
If you think this is just hype, look at the recent research coming out of Microsoft. They recently published extensive work on GraphRAG, demonstrating that it solves a massive class of problems they call “Global Discovery” queries.
Standard RAG is good at “local” queries (finding a needle in a haystack). GraphRAG excels at “global” queries that require summarizing disparate information across the entire dataset, like “What are the major recurring themes regarding infrastructure failures across all project post-mortems in 2026?”
Microsoft found that by structuring data as a graph and using an LLM to traverse communities of related nodes, they could generate comprehensive answers that baseline RAG couldn’t even approach.
The Architecture: Building the Modern GraphRAG Stack
This sounds great, but it’s harder to build than a 5-minute LangChain vector tutorial. Building a Knowledge Graph requires more upfront engineering effort.
Here is what the mature stack looks like in late 2025 for engineers serious about this capability.
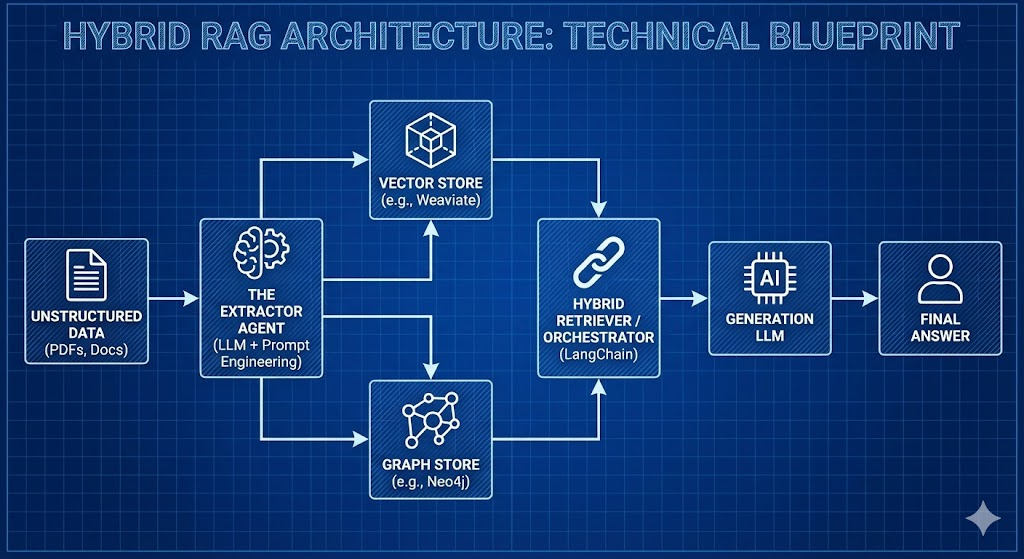
1. The Hardest Part: Knowledge Extraction
How do you turn a messy PDF into neat Nodes and Edges? You can’t just regex your way through it. You need AI to build the AI’s database.
We use an “Extractor LLM” (usually a powerful model like GPT-4o or a heavily fine-tuned Llama 3 70B) and pass the text through it with highly specific prompts instructed to identify entities and define the relationships between them.
The output isn’t an embedding; it’s a list of structured “triples” (Subject, Predicate, Object). This is the most compute-intensive part of the pipeline, but it only needs to happen once during ingestion.
2. The Storage Layer: Neo4j is King
While you could technically use a Python library like NetworkX for small, in-memory graphs, enterprise-grade AI demands a real Graph Database.
Neo4j remains the industry standard here. It’s robust, scalable, and has incredible integrations with the AI ecosystem. They have introduced vector indexing within the graph nodes themselves, which is a massive advantage (more on that in a minute). Other players like ArangoDB or Amazon Neptune are also viable depending on your cloud ecosystem.
3. The Orchestration Layer: LangChain & LlamaIndex
Thank goodness we don’t have to write raw Cypher queries (Neo4j’s query language) manually every time.
Both LangChain and LlamaIndex have matured significantly in this area. They provide abstractions that allow an LLM to:
- Interpret a user question.
- Autogenerate the necessary Cypher query to explore the graph.
- Execute the query and retrieve the structured subgraph.
- Synthesize that structured data into a natural language response.
Also Read:The Junior Developer Crisis is Real
The Pro Move: The Hybrid Approach
So, do we throw away our Vector DBs? absolutely not.
Vectors are still faster and cheaper for broad, fuzzy searches. Graphs are superior for structured reasoning and multi-hop connections.
The best architectures right now use a Hybrid RAG approach.
When a query comes in:
- Parallel Execution: The system runs a vector search to find broadly relevant documents AND a graph traversal to find specific connected entities.
- Reranking: The results from both retrieval methods are combined and consolidated.
- Context Window: The very best context from both worlds is fed to the final LLM.
This gives you the “fuzzy match” capability of vectors combined with the “verifiable accuracy” of a knowledge graph.
The Takeaway
We are rapidly moving past the “Hello World” era of generative AI wrappers. The differentiator between a junior developer hacking together APIs and a senior AI engineer is system architecture.
Anyone can pass text to an embedding model. But designing a system that truly mirrors the complexity and interconnectedness of your organization’s knowledge? That’s where the real value lies.
Stop forcing your AI agents to guess based on loose similarity. Give them a map. Start building graphs.